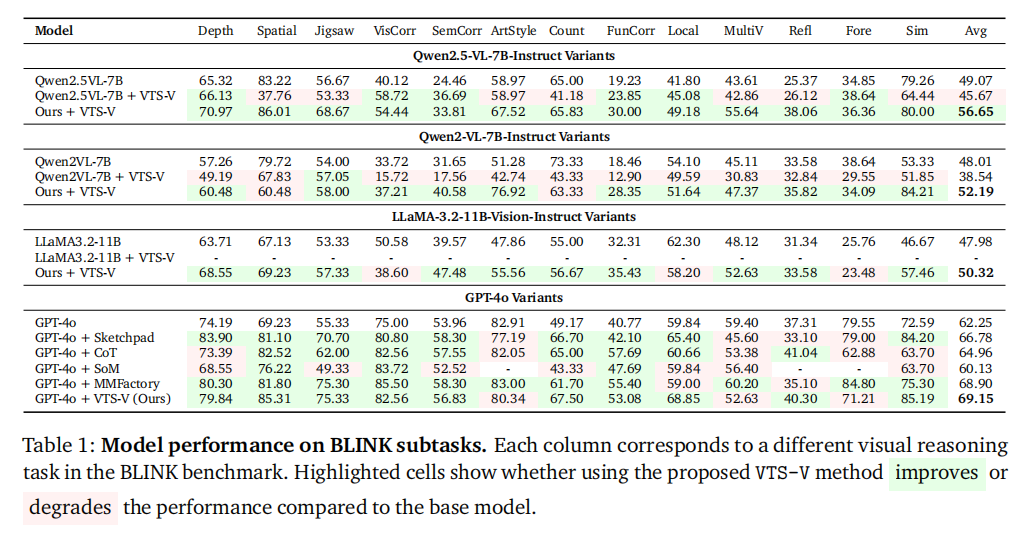
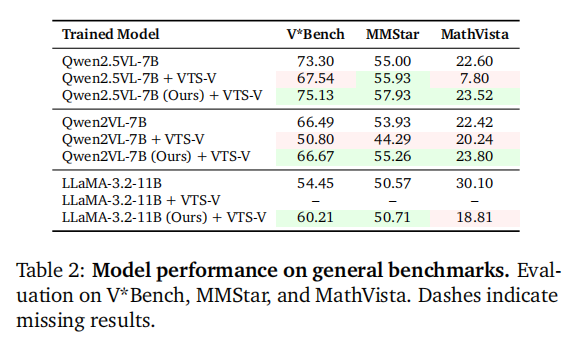
Method

Iterative Visual Reasoning with VTS-V.
Our framework equips both open-source and closed-source models with dynamic visual token scaling and step-wise verification to solve complex visual tasks. The example shows how VTS-V: (1) decomposes questions into executable steps, (2) invokes vision tools, and (3) iteratively refines answers via verifier feedback, achieving correct results. In contrast, vanilla models fail to ground detailed visual operations without token scaling, leading to incorrect answers.
Data Construction Pipeline
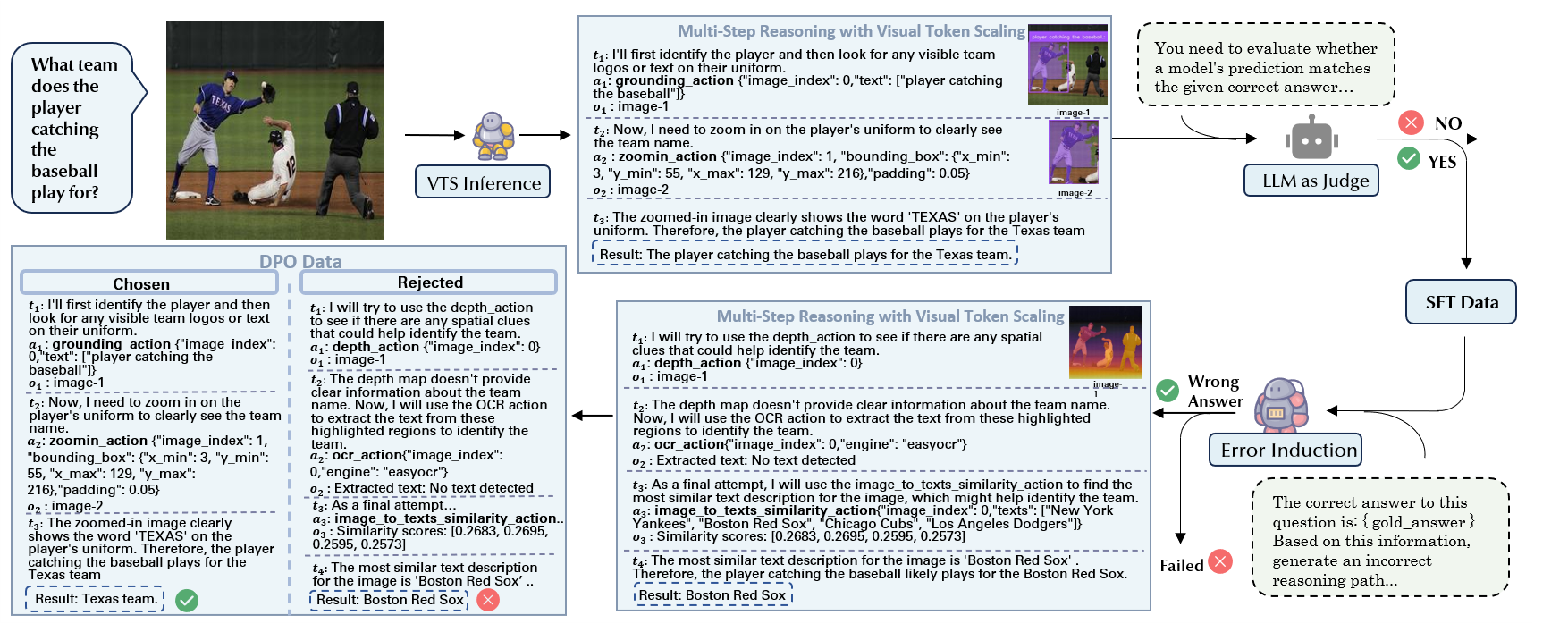
Pipeline for Synthetic Data Generation and Curation in VTS-V
Our data construction process consists of three stages: (1) generating multi-step reasoning trajectories with visual tool calls, (2) filtering out incorrect trajectories using an LLM-as-a-judge framework, and (3) creating contrastive (correct vs. incorrect) trajectory pairs for multi-step DPO training.